


For more than 20 years, Google has been organizing information from the internet. Now, it’s trying to grasp the finer points of how people speak and write, all to make your online searches even better.
Facebook
Twitter
LinkedIn
Pinterest
Pocket
WhatsApp

What does the future of internet search hold? Google envisions it resembling a friendly chat with a pal.
Despite Google’s search engine being around for more than 20 years, the technology behind it keeps advancing. The company has now unveiled a fresh AI system called MUM, short for Multitask Unified Model. MUM is built to grasp the finer points of human language on a global scale. This could make it simpler for users to locate the information they seek or even ask more abstract questions.
Google has already employed MUM in a standalone project to gain insights into the various ways people discuss COVID vaccines. However, Google clarifies that this cutting-edge technology has not yet been integrated into their regular search system.
While there’s no fixed schedule for its official launch in live search, the team is actively engaged in creating other specific tasks for MUM to handle. Here’s what you should be aware of regarding MUM: its unique attributes, distinctions from previous technologies, and more.

Meeting MUM at Google I/O
We got our first glimpse of MUM during the Google I/O developer’s conference in the spring, when Prabhakar Raghavan, Google’s Senior Vice President, introduced it.
The new technology represents the natural progression of Google’s machine-learning-based search, a field the company has been fine-tuning for the past decade. Google proudly claims that MUM possesses the ability to acquire extensive knowledge about the world, comprehend language, and even generate it.
Moreover, it can simultaneously work across 75 different languages. Internal tests are also underway to determine if MUM can be multimodal, meaning it can understand various types of information like text, images, and videos all at once.
The complexity of MUM becomes apparent through a simple example shared during the conference and in a blog post. Imagine asking Google, ‘I’ve hiked Mt. Adams and now want to hike Mt. Fuji next fall, what should I do differently to prepare?’ This is a type of query that most people wouldn’t typically enter into a search engine today because users understand that it’s not how you typically seek information online.
Prabhakar Raghavan explained at the I/O event that ‘This is a question you would casually ask a friend, but search engines today can’t answer it directly because it’s so conversational and nuanced.’ However, in an ideal scenario, MUM would comprehend that you’re comparing two mountains and that ‘prepare’ could encompass aspects such as fitness training for specific terrain and appropriate hiking gear for fall weather.
It would break down your query into a series of related questions, learn about each aspect of your problem, and then provide a comprehensive response. Users could also explore search results related to each aspect of the question and receive an overarching explanation of how the initial query was addressed.
Experiences like these are the ultimate goals for MUM’s engineers, although the timeframe for achieving them remains uncertain. In the medium term, Google’s engineers are focusing on training MUM to recognize the connections between words and images, which has shown promising progress. According to Nayak, when they tasked MUM with generating an image for a new piece of text, such as ‘Siberian Husky,’ it performed impressively.
A Brief History of Search
Google, since its launch in 1998, has been on a relentless mission to map the vast landscape of the internet, collecting and organizing its vast trove of content into what is known as the Google search index.
Think of the Google search index as akin to the index found at the back of a book, but with some significant differences. In a book, the index helps you locate pages where specific words appear, typically in a structured and relatively limited set of pages, often ranging from 300 to 1,000. However, when it comes to the internet, the scale is vastly different, with trillions of web pages to index.
Another critical distinction is that in a book’s index, you search for one word at a time. In the online realm, you’re searching for combinations of words, which opens up a world of complexity. As Google’s Nayak points out, billions of queries pour in from around the world every day due to this immense scale and the explosion of word combinations. What’s truly remarkable is that a substantial 15 percent of these daily searches are entirely new, never before encountered by the search engine. This reveals an incredible degree of novelty in the queries posed by users.
This novelty can be attributed, in part, to innovative ways people misspell words. However, it also arises because the world is in a constant state of change, leading to new and sometimes highly specific inquiries from users seeking information.
Certainly, software can’t fully grasp language in the nuanced and subtle way humans do. However, software engineers can employ various strategies to come close to our understanding of language. Over 16 years ago, Google developed the initial version of its synonym system, recognizing that words can carry different meanings in different contexts. For instance, the word “change” can mean “adjust” when discussing laptop brightness. Without accounting for this, many relevant web pages might have been excluded from search results due to variations in word choice.
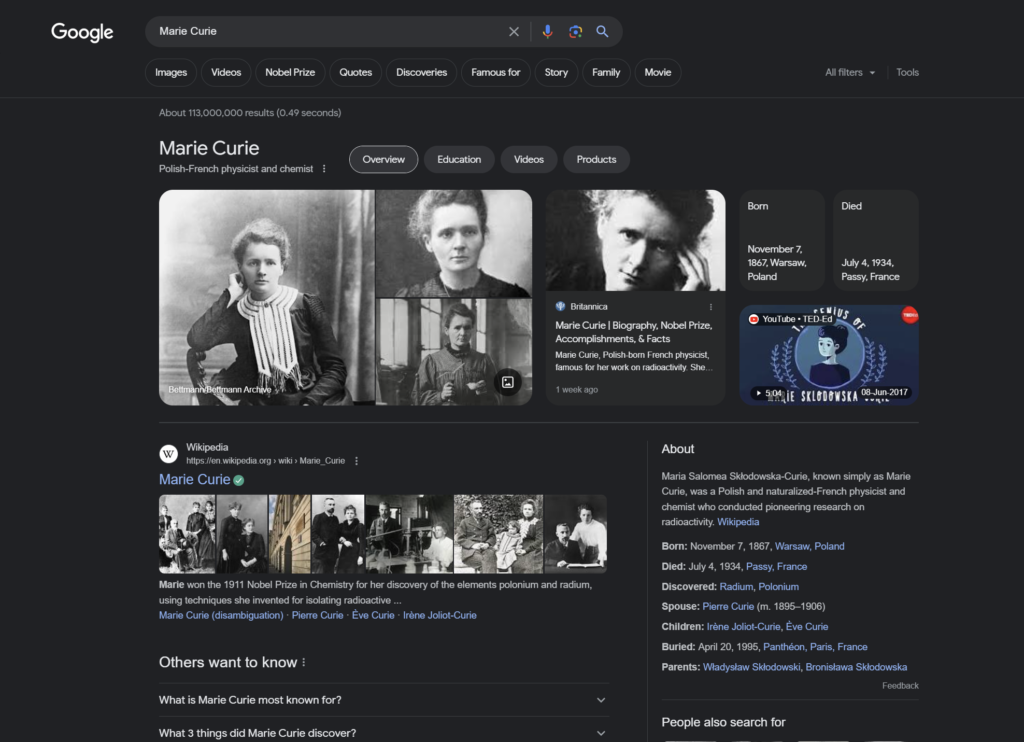
For instance, if you were to search for “Marie Curie,” Google’s knowledge graph can provide detailed information about her, including her birth date and place, her spouse, children, alma mater, and her notable accomplishments. This knowledge graph serves as a convenient way to present information beyond the list of web page results that Google typically displays following a search.
Machine Learning Advancements Take Center Stage
Approximately six years ago, Google introduced its first iteration of machine learning-powered search. Since then, Google has been on a continuous journey to enhance this technology, drawing from extensive research within the deep learning community. This research focuses on natural language algorithms capable of understanding word meanings in context and determining which parts of that context are most relevant. A significant milestone arrived in 2019 with the introduction of the BERT architecture for search.
BERT’s training algorithm essentially resembled a set of “fill in the blanks” exercises. Common phrases had random words blocked out, and the network’s task was to predict these missing words. This approach is also referred to as a masked language model.
In the past, when someone queried, “can you get medicine for someone at the pharmacy,” the search results typically revolved around picking up prescriptions at the pharmacy. However, with the introduction of BERT, it began to comprehend that the query wasn’t just about obtaining a prescription but specifically about acquiring one for someone else, be it a friend or a family member.
As Nayak puts it, “We were able to provide a more relevant result because BERT picked up on the nuances in the question that we previously couldn’t address.”
MUM, unlike BERT, not only comprehends language but can also generate it. It’s significantly larger and more potent, roughly 1,000 times more powerful than BERT. MUM undergoes training using a high-quality selection from the public web corpus, encompassing all languages supported by Google. The search team takes great care to remove low-quality, & hate-filled content, aiming for a more positive language base.
Simultaneous training across multiple languages allows MUM to generalize information from data-rich languages to those with limited data, effectively bridging gaps in training. However, MUM does face challenges, particularly regarding bias. Training from the web corpus raises concerns about reflecting or perpetuating biases.
While the use of a high-quality subset helps mitigate this issue, Google employs search quality raters and other evaluation processes to address potential problems and patterns. While it doesn’t eliminate challenges, it represents a significant step in addressing them.
Features like autocomplete have indeed aimed to simplify the search process, but MUM could usher in a fresh array of possibilities. As Nayak puts it, “The ultimate question when it comes to all search tools, considering they are tools, is: Even if it’s not flawless, is it valuable?”
Facebook
Twitter
LinkedIn
Pinterest
Pocket
WhatsApp
Never miss any important news. Subscribe to our newsletter.
Related News


Top 10 Winter Wellness Tips!
July 3, 2026

Explore York: 5 Heritage Pubs for History Buffs
July 3, 2026


The Impact of AI on Every Scientific Frontier
July 3, 2026


Burning Waste Becomes UK’s Dirtiest Energy Source
July 3, 2026

What causes autumn leaves to change their color?
July 3, 2026

Telephone’s Inventor: Who was it?
July 3, 2026

